Hyperledger Fabric在联盟链领域表现卓越,集合了众多才智。尤其是v1.1版本的kafka共识机制,其处理能力十分显著。这背后有何奥秘?这些优势又是如何在实际应用中体现的?让我们共同揭开这个谜题。
Hyperledger Fabric的背景
IBM、Intel等众多企业及银行共同参与了Hyperledger Fabric核心代码的开发。这主要是因为众多企业意识到Hyperledger Fabric在区块链联盟链领域的巨大潜力。以银行为例,在处理大量金融交易时,他们迫切需要一个既安全又高效的区块链平台,Hyperledger Fabric恰好满足了这一需求。Hyperledger Fabric社区集合了各方资源,持续优化升级,现在已发展至较为成熟、具备高吞吐量的v1.1版本。
在具体操作中,以某些国际知名银行为例,在进行跨国结算时,便需依赖一种能高效处理众多交易的共识系统。Hyperledger Fabric的v1.1版所采用的kafka共识系统,其处理速度可达每秒1000次,确保了交易能迅速完成,有效防止了交易拥堵。
分布式账本概念
分布式账本技术构成了区块链的根基。这种技术让网络中的每个节点,除了客户端,都存储了相同的完整交易账本信息。比如,在一个由10个节点组成的区块链网络中,任一节点都能查阅到所有交易的历史记录。但这一特性同时也引发了一些难题。
账本的尺寸受限于区块链网络中最小节点的存储与处理能力。假如某个节点的存储空间只有100G,账本的数据量就不能超过这个上限。在实际操作中,这会影响到交易数据的总数,还会对每条交易数据的大小造成限制。以存储资源有限的数据中心为例,可能必须对交易数据的大小进行限制。
关于区块链的定义
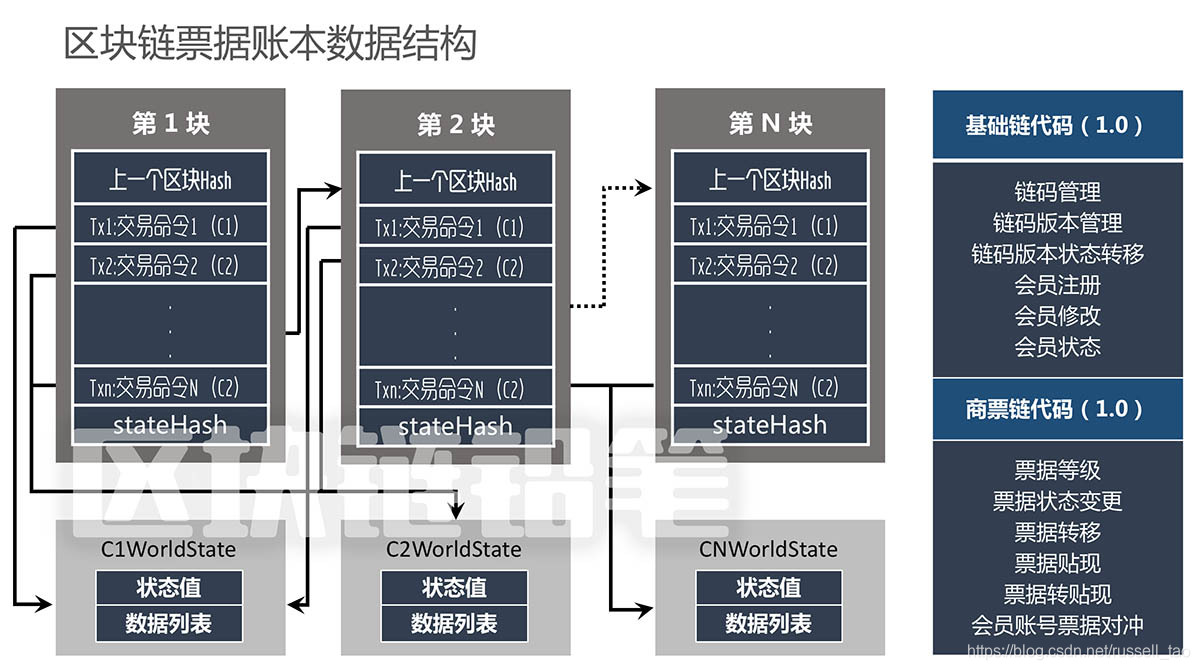
依据专业书籍的阐述,区块链是一种特定的数据组织形式,它将数据区块按照时间的先后顺序逐一串联。这可以比作一本按时间顺序编排的账簿,每当有新的交易数据产生,就会附加到链的末端。在现实中的区块链系统中,每一笔交易都是按照发生的顺序被记录下来的。
这种链式结构使得安全性较高,因为若想对其中一条信息进行篡改,就得对之后的所有信息都进行修改。比如,在一个包含100条交易信息的区块链中,若要修改第50条信息,那就必须对从第50条到第100条的所有信息进行篡改,这在分布式的网络环境中几乎是不可能完成的。
智能合约的作用
智能合约是运行在区块链上的程序脚本,它具有模块化和可重复使用的特性,能够自动执行任务。在处理复杂业务逻辑时,智能合约发挥着至关重要的作用。例如,当多个企业合作时,一份智能合约可以明确说明甲企业需要提供原材料,而乙企业则需负责进行深加工。
每份合同允许设定不同的参与主体。在fabric平台上,存在一种共识机制。该机制允许指定哪些企业的节点可以参与交易。以某产品的生产供应链为例,区块链合同可以明确规定原材料供应商和加工商的节点必须参与交易,而物流等相关企业的节点则不包含在内。
区块链的一致性
区块链是一种去中心化的网络体系,它通过投票确保数据一致性,并执行少数服从多数的规则。以fabric平台上的v1.1版kafka共识机制为例,该机制使用的是复杂度为O(N)的算法。这种算法在不同应用环境下,其效果可能会有所不同。
网络节点较少时,此算法执行速度可能更快。然而,在拥有众多节点的庞大区块链网络中,可能需要对算法进行改进,或者选择更适宜的算法,以维护系统的稳定运行。
Hyperledger Fabric的模块与开发人员分工
织物主要由三个部分构成:网络基础层、权限分配模块以及区块链应用层。SDK和CLI工具为开发者提供了必要的辅助。网络基础层主要负责节点间的沟通与互动;权限分配模块则负责为不同用户和节点合理地分配相应的权限。
业务开发人员负责编写chaincode、搭建并维护channel、执行transaction交易等工作。以开发一个全新的企业间供应链区块链应用为例,他们需要编写智能合约代码,创建合适的channel来区分不同组织,并完成交易过程。
你如何看待Hyperledger Fabric在发展过程中,哪些方面最为关键需要改进?